

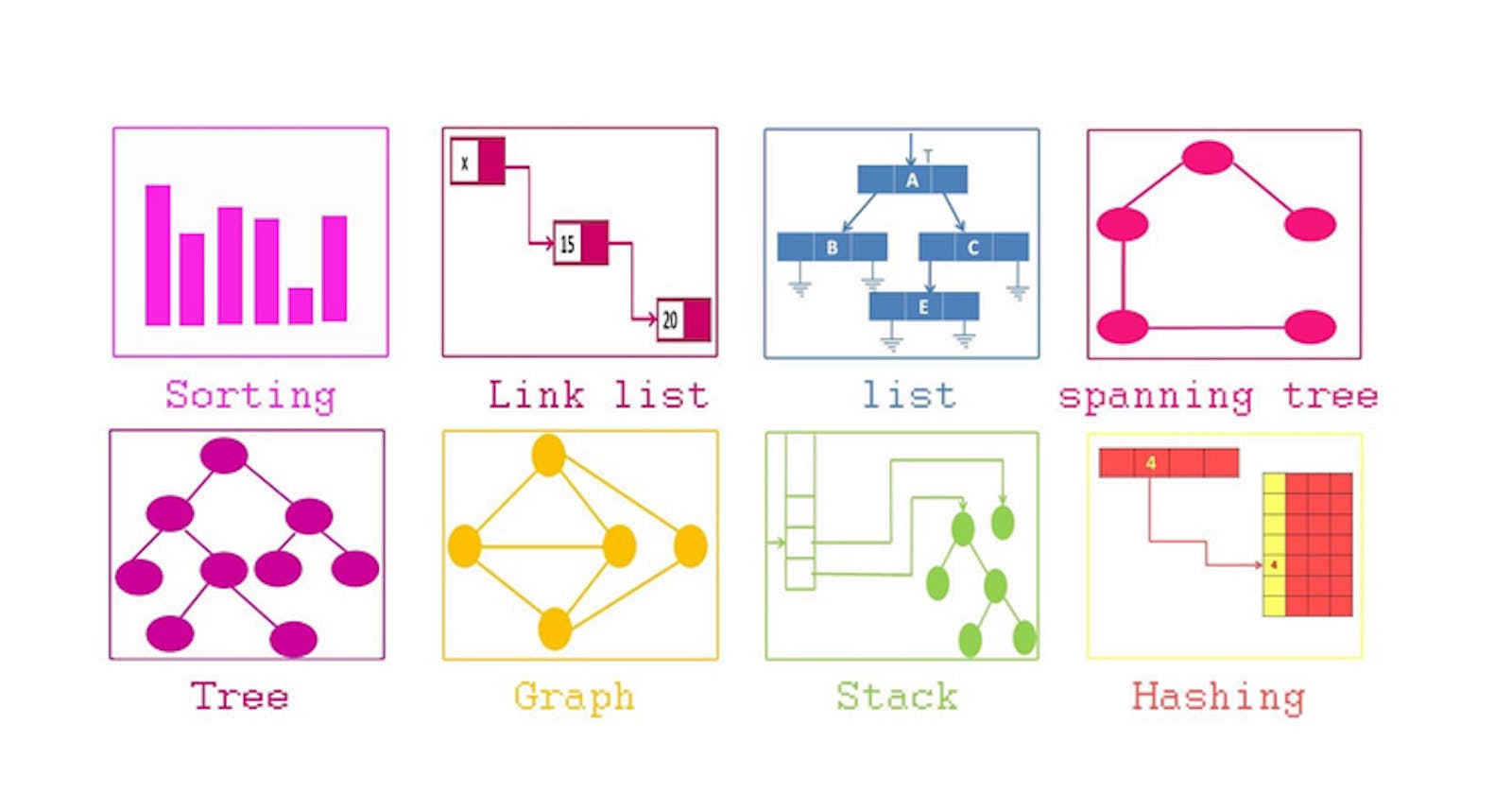


Data structures refer to a way of organizing and storing data in a computer's memory so that it can be accessed and manipulated efficiently. Data structures are fundamental to computer science because they enable efficient organization and retrieval of data.
Usability
Data structures are used in nearly all areas of computer science, including data processing, file management, database systems, graphics, and artificial intelligence. Understanding data structures and their implementations is crucial for developing efficient algorithms that can process and manipulate large amounts of data.
In addition to choosing the right data structure for the task, it is also important to consider how to implement the data structure in a way that maximizes efficiency and minimizes memory usage. This involves selecting appropriate algorithms for different operations on the data structure such as insertion, deletion, searching, and sorting.
Well Known
There is a wide variety of data structures that are used in computer science, each with its own advantages and disadvantages depending on the task at hand. Some of the most common data structures include arrays, linked lists, stacks, queues, binary trees, hash tables, and graphs.
Here are some common data structures and their descriptions:
Arrays: Arrays are a collection of similar data items that are stored in contiguous memory locations with a single name. It allows efficient access to any element, but inserting or deleting elements can be time-consuming.
Linked Lists: Linked Lists consist of nodes that are connected to each other using pointers. It allows efficient insertion and deletion in the middle of the list but accessing an element takes more time as it must be traversed from the beginning.
Stacks: Stacks support LIFO (Last-In-First-Out) order, where the last element inserted is the first one to be removed. It has two main operations: push, which adds an element to the top of the stack, and pop, which removes the top element.
Queues: Queues support FIFO (First-In-First-Out) order, where the first element inserted is the first one to be removed. It has two main operations: enqueue, which adds an element to the end of the queue, and dequeue, which removes the first element.
Trees: Trees are hierarchical data structures with a root node and any number of child nodes connected by edges. Trees can be binary (each node has at most two children) or multi-way (each node can have more than two children).
Graphs: Graphs consist of a set of vertices and edges that connect them. They can be directed (edges have a direction) or undirected (edges do not have a direction).
Hash Tables: Hash tables use a hash function to map keys to an index in an array, allowing constant-time access to elements. However, collisions (when multiple keys map to the same index) can cause performance issues.
These are just a few examples of the many data structures used in computer science. Choosing the right data structure for the task at hand is important for efficient program design.
Features
Here are some of the features, advantages, and disadvantages of each data structure. Read slowly and take notes but don't be worried. You will relearn all these structures in details for every programming language.
1 - Arrays:
Features:
Elements are stored in contiguous memory locations
Allows for efficient access and search of elements
Advantages:
Simple to understand and use
Constant time access to elements
Disadvantages:
Inserting and deleting elements can be time-consuming, as all subsequent elements must be shifted to fill the gap
The size of the array is fixed, which can be limiting and result in wasted memory if the array is not completely filled.
2 - Linked Lists:
Features:
Elements are stored in separate memory locations linked by pointers
Can grow and shrink as needed
Advantages:
Insertion and deletion of elements can be done efficiently in constant time
Flexible size and dynamic memory allocation
Disadvantages:
Accessing an element takes more time as it must be traversed from the beginning
Extra memory is required for storing the pointers
3 - Stacks:
Features:
Follows the LIFO (Last-In-First-Out) principle
Two main operations - push and pop
Advantages:
Simple to understand and use
Well-suited for certain algorithms such as recursion, backtracking, and expression evaluation
Disadvantages:
Only allows access to the top element
Can cause stack overflow errors if too many elements are pushed onto the stack
4 - Queues:
Features:
Follows the FIFO (First-In-First-Out) principle
Two main operations - enqueue and dequeue
Advantages:
Well-suited for certain algorithms such as BFS (breadth-first search)
Can be implemented using other data structures such as linked lists and arrays
Disadvantages:
Can cause queue overflow errors if too many elements are enqueued
Only allows access to the front and rear elements
5 - Trees:
Features:
Consists of nodes connected by edges
Can be binary (at most 2 children per node) or multi-way
Advantages:
Efficient for search and manipulation of hierarchical data
Well-suited for certain algorithms such as binary search and decision trees
Disadvantages:
Requires extra memory for storing pointers
Tree imbalance can cause slower search time
6 - Graphs:
Features:
Consists of vertices and edges
Can be directed or undirected
Advantages:
Well-suited for a wide range of problems, such as social networks, transportation networks, and web links
Provides a powerful model for solving problems with interconnected data
Disadvantages:
Can be more complex to implement than other data structures
Traversing can be time-consuming and require extra memory for storing visited nodes.
7 - Hash Tables:
Features:
Elements stored in an array indexed by a hash function
Constant time access to elements
Advantages:
Efficient for searching and inserting elements in large data sets
Provides high-speed lookups and updates
Disadvantages:
Collisions can occur, slowing down results
Not suitable for order dependent data
Exotic structures
There are several exotic data structures that are not commonly used but can be very effective in specific scenarios. Here are some examples:
Bloom Filter - A probabilistic data structure used for quickly checking whether an element is present in a set. It has space-efficient characteristics and can give false positives but no false negatives.
Skip List - A probabilistic data structure that allows for fast search, insertion, and deletion of elements in a set. It is a linked list with multiple layers that allows skipping over certain elements to minimize search times.
Suffix Tree - A data structure used for efficient substring search in a given string. It stores all suffixes of a string as a tree structure, making it useful for substring and subsequence matching.
Trie - A tree-like data structure used for efficient string search, storage, and retrieval. It stores a set of strings and can find them based on their prefix.
Van Emde Boas Tree - A tree-based data structure used for efficient search, insertion, and deletion of integers in a given range. It is commonly used in computational geometry and database applications.
Fenwick Tree (also known as Binary Index Tree) - A data structure used for quickly computing cumulative sums and updating individual values in an array. It is commonly used in computer science algorithms such as suffix arrays and variant analysis.
These data structures can be very useful in specific situations, but may not be necessary or efficient for all use cases.
Large strings
When it comes to representing large strings, there are several data structures that can be used, each with its own advantages and disadvantages. Here are some examples:
Array: One simple way to represent a string is to use an array of characters. The advantage of using an array is that it is simple and easy to work with. However, the downside is that it can be inefficient for large strings, as it requires a contiguous block of memory, which may not always be available.
Linked List: Another option is to use a linked list of characters. This can be useful because it allows for efficient insertions and deletions in the middle of the string. However, it can be less efficient for accessing individual characters, as it requires traversing the list.
Rope: A rope is a data structure that represents a string as a tree of smaller strings. Each node of the tree contains a small string, and the root node represents the full string. This data structure can be very efficient for accessing and manipulating large strings, as it allows for fast concatenation, splitting, and order statistics. However, it can be more complex to implement than simpler data structures like the array or linked list.
Suffix Array: A suffix array is an array that stores the starting positions of all suffixes in a string, sorted lexicographically. This data structure can be useful for substring matching and other string algorithms, but may not be as efficient for other operations like insertion and deletion.
Trie: A trie is a tree-based data structure that can be used to efficiently store and search for strings. Each node of the tree represents a prefix of one or more strings, and the edges represent individual characters. This data structure can be useful for searching for a large number of strings, but may not be as efficient for other operations like concatenation and splitting.
Choosing the right data structure for a large string depends on the specific use case and requirements, taking into consideration factors such as access patterns, size of string, and frequency of updates.
Conclusion
Overall, data structures are an essential component of computer science and are critical to building high-performance computer programs. They are a fundamental building block of many complex algorithms and systems that are essential to modern computing.
Disclaim: This article is entirely generated by ChatGPT. I have ask the right questions to create this article for you to start learning. Now you can dig into it for a specific programming language. Good luck 🍀
Note: If you find any errors, blaim ChatGPT and comment so I can fix it.
Enjoy life, learn and prosper 🖖🏼